did you break your code or is the test flaky?
A fail-safe checklist for how you can tell the difference

Flaky end-to-end tests are frustrating for quality assurance (QA) and development teams, causing constant disruptions and eroding trust in test outcomes due to their unreliability.
We'll go over all you need to know about flaky tests, how to spot a flaky test from a real problem, and how to handle, fix, and stop flaky tests from happening again.
Are flaky tests a real issue?
While often ignored, flaky tests are problematic for QA and Development teams for several reasons:
- Lack of trust in test results
When tests are unreliable, developers and QA teams may doubt the validity of the results, not only for those specific tests but also for the entire set. - Wasted time and resources
The time and resources wasted diagnosing flaky tests could've been spent adding value to the business. - Obstructed CI/CD pipelines
Constant test failures that are unreliable often result in the need to run tests again to ensure success, causing avoidable delays for downstream CI/CD tasks like producing artifacts and initiating deployments. - Masks real issues
Repeated flaky failures may lead QA and Developers to ignore test failures, increasing the risk that genuine defects sneak through and are deployed to production.
What causes flaky tests?
Flaky tests are usually the result of code that does not take enough care to determine whether the application is ready for the next action.
Take this flaky test Playwright test written in Python:
1 page.click('#search-button')
2 time.sleep(3)
3 result = page.query_selector('#results')
4 assert 'Search Results' in result.inner_text()
Not only is this bad because it will fail if results take more than three seconds —it's also wasting time if the results return in less than three seconds. This is a solved problem in Playwright using the wait_for_selector method:
page.click('#search-button')
result = page.wait_for_selector('#results:has-text("Search Results")')
assert 'Search Results' in result.inner_text()Selenium solves this using the WebDriverWait class:
driver.find_element(By.ID, 'search-button').click()
result = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'search-results'))
)
assert 'Search Results' in result.textFlaky tests can also be caused by environmental factors such as:
- Unexpected application state from testing in parallel with the same user account
- Concurrency and race conditions from async operations
- Increased latency or unreliable service from external APIs
- Application configuration drift between environments
- Infrastructure inconsistencies between environments
- Data persistence layers not being appropriately reset between test runs
Writing non-flaky tests requires a defensive approach that carefully considers the various environmental conditions under which a test might fail.
What is the difference between brittle and flaky tests?
A brittle test, while also highly prone to failure, differs from a flaky test as it consistently fails under specific conditions, e.g., if a button's position changes slightly in a screenshot diff test.
Brittle tests can be problematic yet predictable, whereas flaky tests are unreliable as the conditions under which they might pass or fail are variable and indeterminate.
Now that you understand the nature of flaky tests, let's examine a step-by-step process for diagnosing them.
Step 1. Gather data
Before jumping to conclusions as to the cause of the test failure, ensure you have all the data you need, such as:
- Video recordings and screenshots
- Test-runner logs, application and error logs, and other observability data
- The environment under test and the release/artifact version
- The test-run trigger, e.g. deployment, infrastructure change, code-merge, scheduled run, or manual
You should also be asking yourself questions such as:
- Has this test been identified as flaky in the past? If so, is the cause of the flakiness known?
- Has any downtime or instability been reported for external services?
- Have there been announcements from QA, DevOps, or Engineering about environment, tooling, application config, or infrastructure changes?
Having video recordings or frequently taken screenshots is crucial because it's the easiest-to-understand representation of the application state at the time of failure.
Compile this information in a shared document or wiki page that other team members can access, updating it as you continue your investigations. This makes creating an issue or bug report easy, as most of the needed information is already documented.
Now that you've got the data you need, let's begin our initial analysis.
Step 2. Analyze logs and diagnostic output
Effectively utilizing log and reporting data from test runs is essential for determining the cause of a test failure quickly and correctly. Of course, this relies on having the data you need in the first place.
For example, if you're using Playwright, save the tracing output as an artifact when a test fails. This way, you can use the Playwright Trace Viewer to debug your tests.
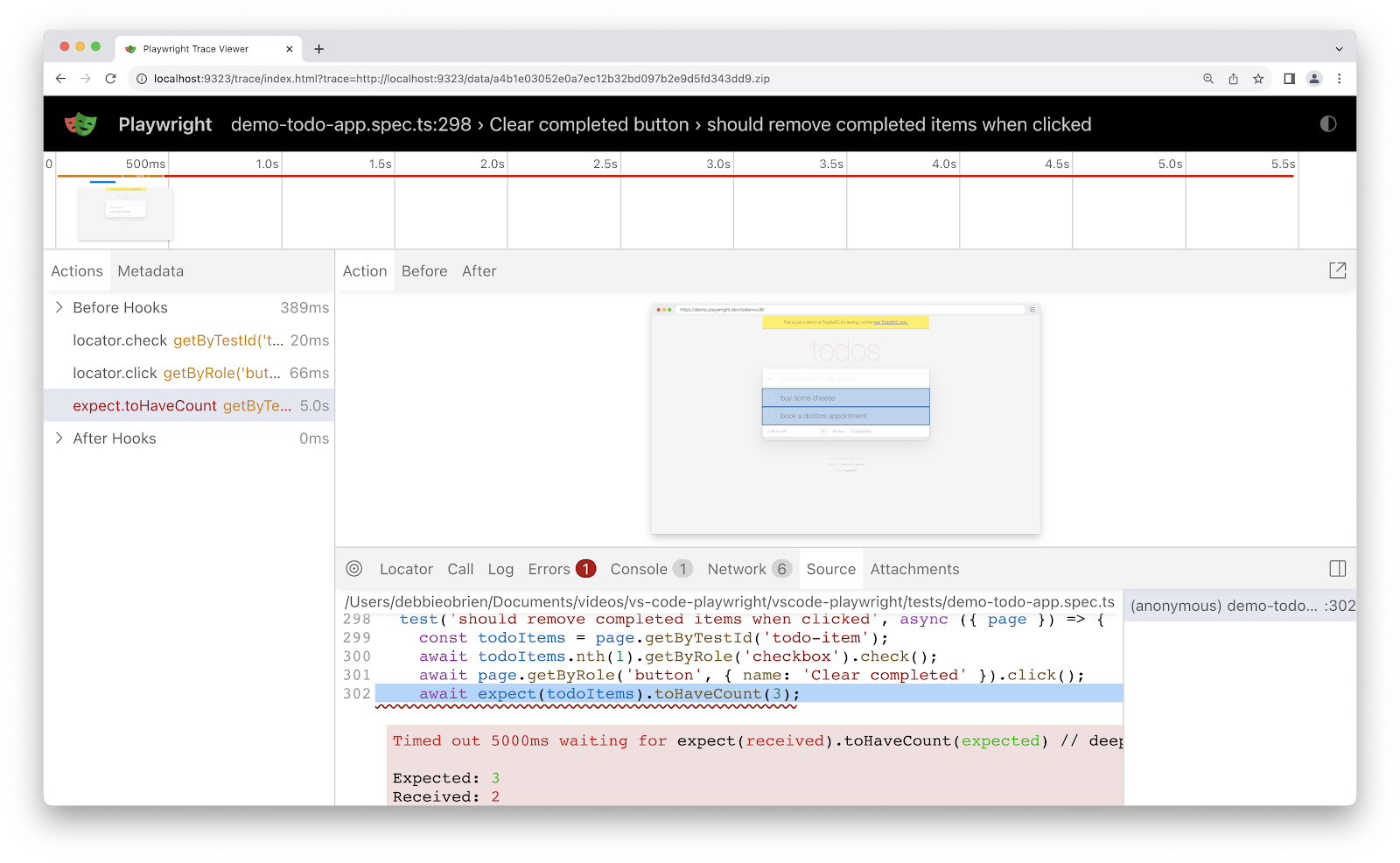
To begin your analysis, first identify the errors to determine if the issue stems from one or a combination of the following:
- Test code failing unexpectedly (e.g. broken selector/locator)
- Test code failing as expected (e.g. failed assertion)
- Application error causing incorrect state or behavior (e.g. JavaScript exception, rejected promise, or unexpected backend API error)
The best indication of a flaky test is when the application seems correct, yet a failure has occurred for no apparent reason. If this type of failure has been observed before, but the cause was never resolved, the test is probably flaky.
Things become more complicated to diagnose when the application functions correctly, yet the state is clearly incorrect. You'll then need to determine if the test relies on database updates or responses from external services to confirm if infrastructure or data persistence layers could be the root cause. Hopefully, your application-level logs, errors, or exceptions will provide some clues.
Debugging test failures is easier when all possible data is available, which is why video recordings, screenshots, and tools such as Playwright's Trace Viewer are so valuable. They help you observe the system at each stage of the test run, giving you valuable context as to the application's state leading up to the failure. So, if you're finding it challenging to diagnose flaky tests, it could be because you don't have access to the right data.
If the test has been confirmed as flaky, document how you came to this conclusion, what the cause is, and, if known, how it could be fixed. Then, share your findings with your team.
Because you've confirmed the test is flaky, re-run your tests, and with any luck, they'll pass the second or third time around. But if they continue to fail, or you're still unsure why the test is flaky, more investigation is required.
Step 3. Review recent code changes
If the test run was triggered by an application or test code changes, review the commits to look for updates that may be causing the tests to fail. For example, newly added tests that aren't cleaning up their state executing before the now-failing test.
Also, check for changes to application dependencies and configuration.
Step 4. Verify the environment
If your flaky tests still fail after multiple re-runs, it's likely that application config, infrastructure changes, or third-party services are responsible. Test failures caused by environmental inconsistencies and application drift can be tricky to diagnose, so check with teammates to see if this kind of failure has been seen before under specific conditions, e.g. database server upgrade.
Running tests locally to step-debug failures or in an on-demand isolated environment is the easiest way to isolate which part of the system may be causing the failure. We have open sourced a tool to do exactly that - our Debugtopus. Check it out in our docs or go directly to the Debugtopus repo.
Also, check for updates to testing infrastructure, such as changes to system dependencies, testing framework version, and browser configurations.
Reducing flaky tests
While this deserves a blog in its own right, a good start to preventing flaky tests is to:
- Ensure each test runs independently and does not depend implicitly on the state left by the previous tests.
- Use different user accounts if running tests in parallel.
- Avoid hardcoded timeouts by using waiting mechanisms that can assert the required state exists before proceeding.
- Ensure infrastructure and application configuration across local development, testing, and production remains consistent.
- Prioritize the fixing of newly identified flaky tests as fast as possible.
- Identify technical test code debt and pay it down regularly.
- Promote best practices for test code development.
- Add code checks and linters to catch common problems.
- Require code reviews and approvals before merging test code.
Conclusion
The effort required to diagnose flaky tests properly and document their root cause is time well spent. I hope you're now better equipped to diagnose flaky tests and have some new tricks for preventing them from happening in the future.
We constantly fortify Octomind tests with interventions to prevent flakiness. We deploy active interaction timing to handle varying response times and follow best practices for test generation already today. We are also looking into using AI to fight flaky tests. AI based analysis of unexpected circumstances could help handling temporary pop-ups, toasts and similar stuff that often break a test.

Maximilian Link
Senior Engineer at Octomind