AI doesn't belong in test runtime
Not all AI in e2e testing is created equal
Adopting generative AI in end-to-end testing improves test coverage and reduces time spent on testing. At last, automating all those manual test cases seems within reach, right?
We have to talk about the stability and reliability of AI in this context, too. The concerns are real and I'd like to address a few here.
Testing tools don't use AI in the same way
AI testing tools use AI differently to write, execute and maintain automated tests. The LLMs under the hood are not deployed in the same place in the same way by every testing technology. The AI can be deployed as:
- AI used in runtime: LLM goes into the app and interacts with it every time a test or a test step is executed.
- deterministic code used in runtime: LLMs are used to create interaction representations that translate into deterministic code used during test execution.
What can go wrong?
The good news is that all of the concerns can be mitigated by adopting the right architecture in the right place of testing cycle.
Use AI for test creation
AI is most valuable during the creation and maintenance phase of test cases. Let's take a scripting example. You could begin with a prompt describing your desired test case and allow the AI to generate an initial version.
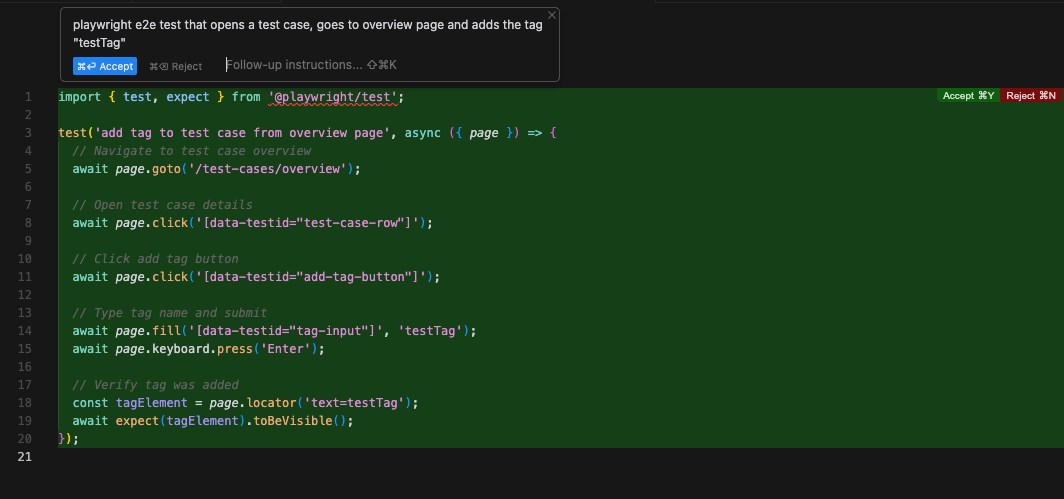
If you're lucky, the AI may produce a valid and ready-to-use test case right away. How convenient!
If the AI struggles to interpret your application, you - the domain expert - can step in and guide it, ensuring that the resulting test case is accurate and robust. It's a good practice to keep AI fallibility on top of your mind when you're accessing its output. It's an even better practice for tool developers to build the reminder into the process.

Do not use AI in test runtime
Ideally, AI should not be used during runtime. It's slow. It's brittle. It's costly. A test case represents an expectation of how a system should work in a particular area. The agentic AI must try to fulfill this expectation. No workarounds. Only if the expectation is formulated precisely enough (code / steps) it can be validated against.
I suggest relying on established automation frameworks such as Playwright, Cypress, or Selenium for test execution. By using standard automation framework code, your test cases can remain deterministic, allowing you to execute them fast and reliably. Some providers even offer execution platforms to scale your standard framework test suites efficiently.
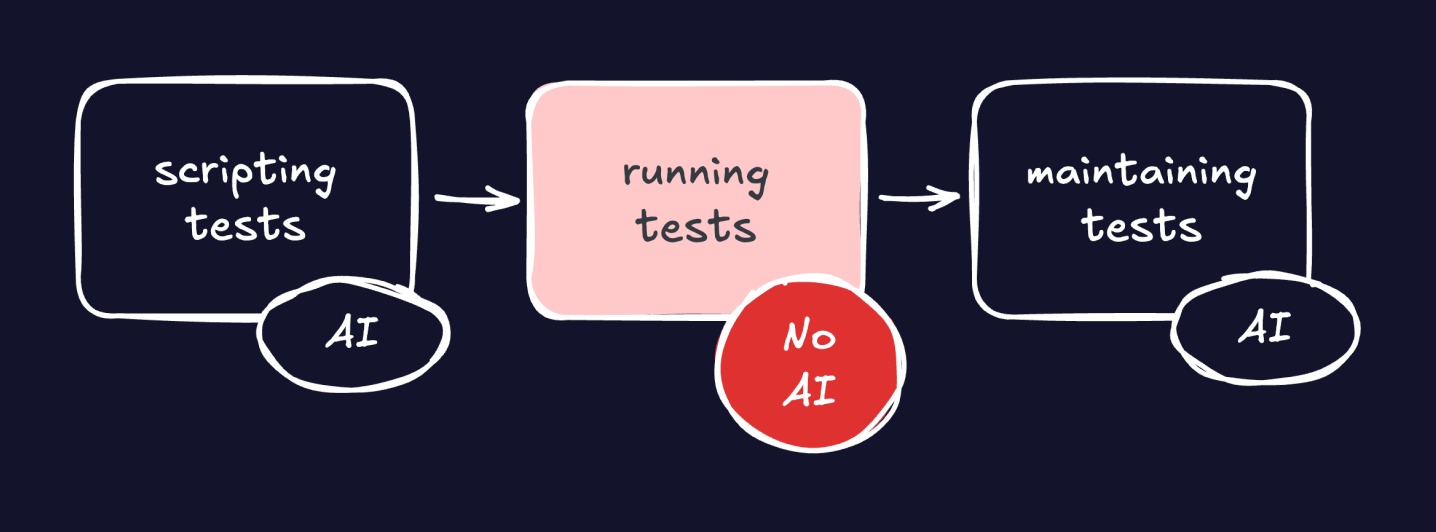
Use AI for test maintenance
The case for using AI in test auto-healing is quite strong. When given boundaries and the 'good example' of the original test case, the AI worst instincts can be mitigated. The idea is that AI generation works best when the problem space is limited.
A robust solution to auto-maintenance would address a huge pain point in end-to-end testing. Maintenance is more time consuming (and frustrating) than scripting and running tests combined. There are many tools building auto-maintenance features using AI right now. If good enough, they could considerably simplify the process of keeping your tests up-to-date and relevant.

Daniel Roedler
Chief Product Officer and Co-founder